Causal Diagrams and Identifying Causal Effects
Directed Acyclic Graphs (DAGs)
Spring 2026
DAG Basics: Nodes and Arrows
Node: A variable in the system.
Each circle represents a variable — either observed or unobserved.
Arrow: \(X \rightarrow Y\) means “\(X\) causes \(Y\).”
- Direction matters (from cause to effect)
- \(X\) is a parent (ancestor) of \(Y\)
- \(Y\) is a child (descendant) of \(X\)

Example: Class Size and Student Achievement
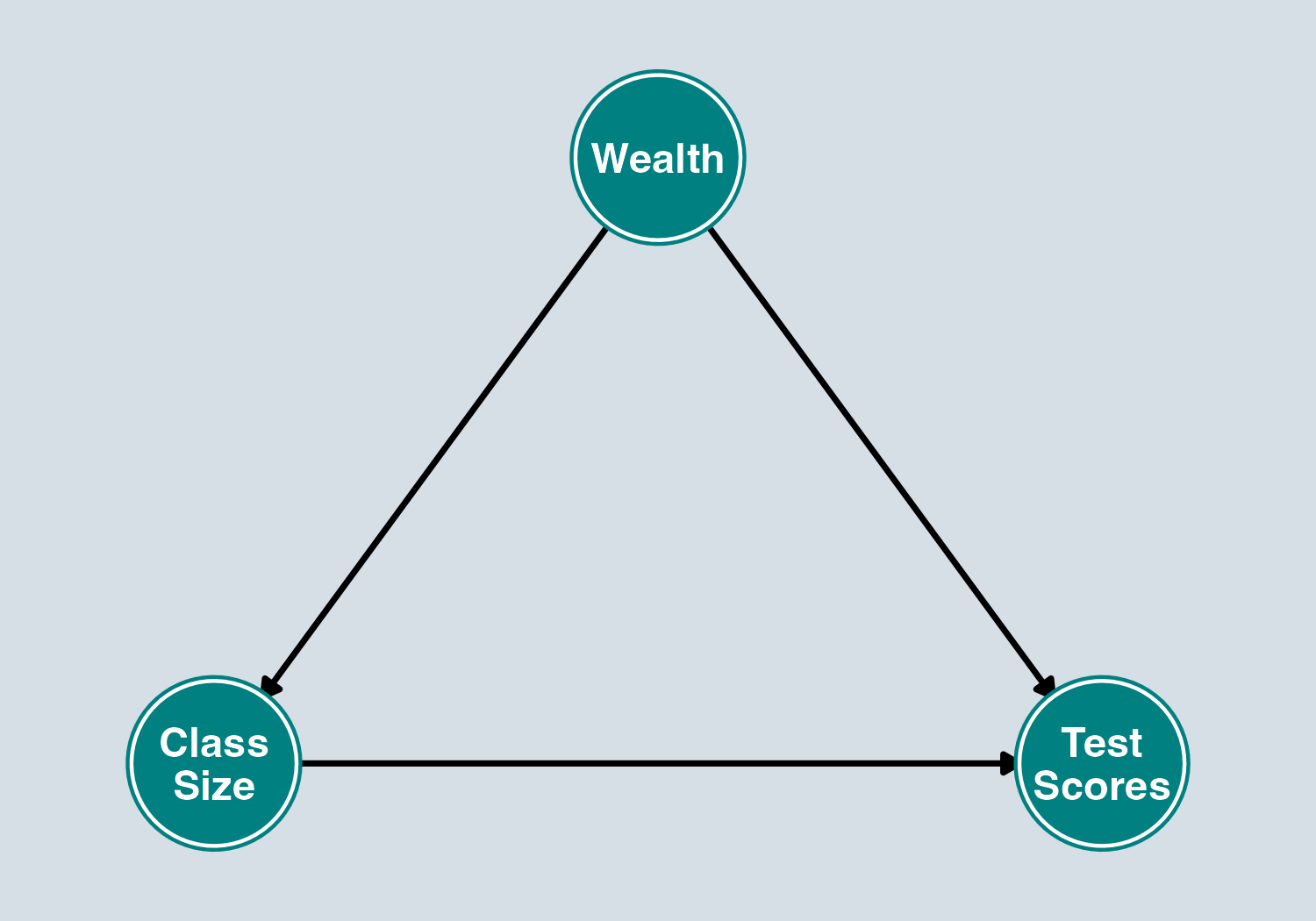
Variables:
- \(X\) = Class Size, \(Y\) = Test Scores, \(Z\) = Wealth
Causal arrows:
- Wealth → Class Size (wealthy areas have smaller classes)
- Wealth → Test Scores (wealthier students score higher)
- Class Size → Test Scores (smaller classes improve learning)
Collider Paths
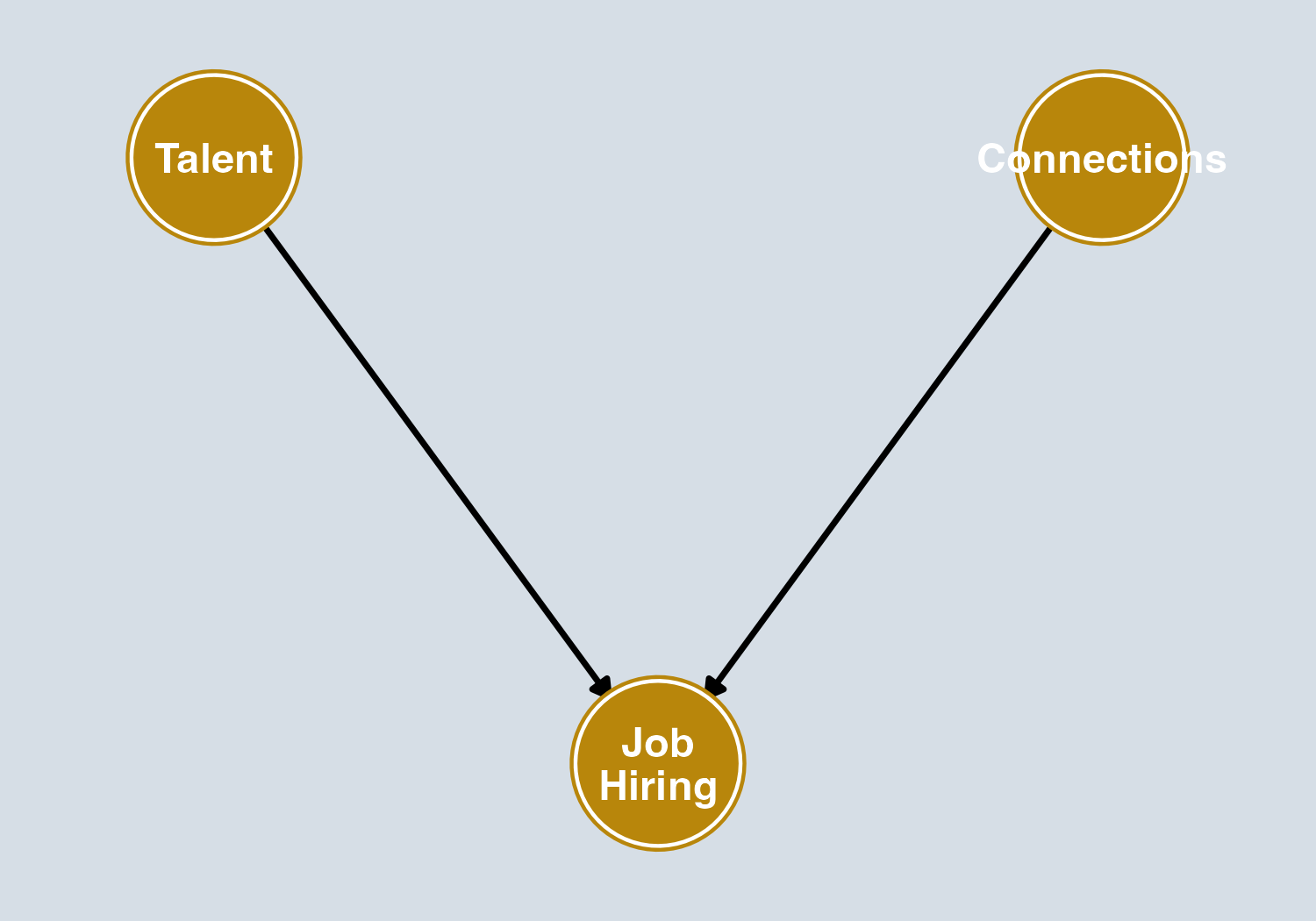
\(X \rightarrow Z \leftarrow Y\)
\(X\) and \(Y\) both cause \(Z\). These paths are closed by default — no confounding flows through them unless we control for \(Z\).
- Talent and Connections both cause Job Hiring
- The path Talent → Job Hiring ← Connections is closed by default
- If we condition on who was hired (control for the collider), the path opens
- Among the hired: low Talent becomes correlated with high Connections
Does Education Cause Earnings?
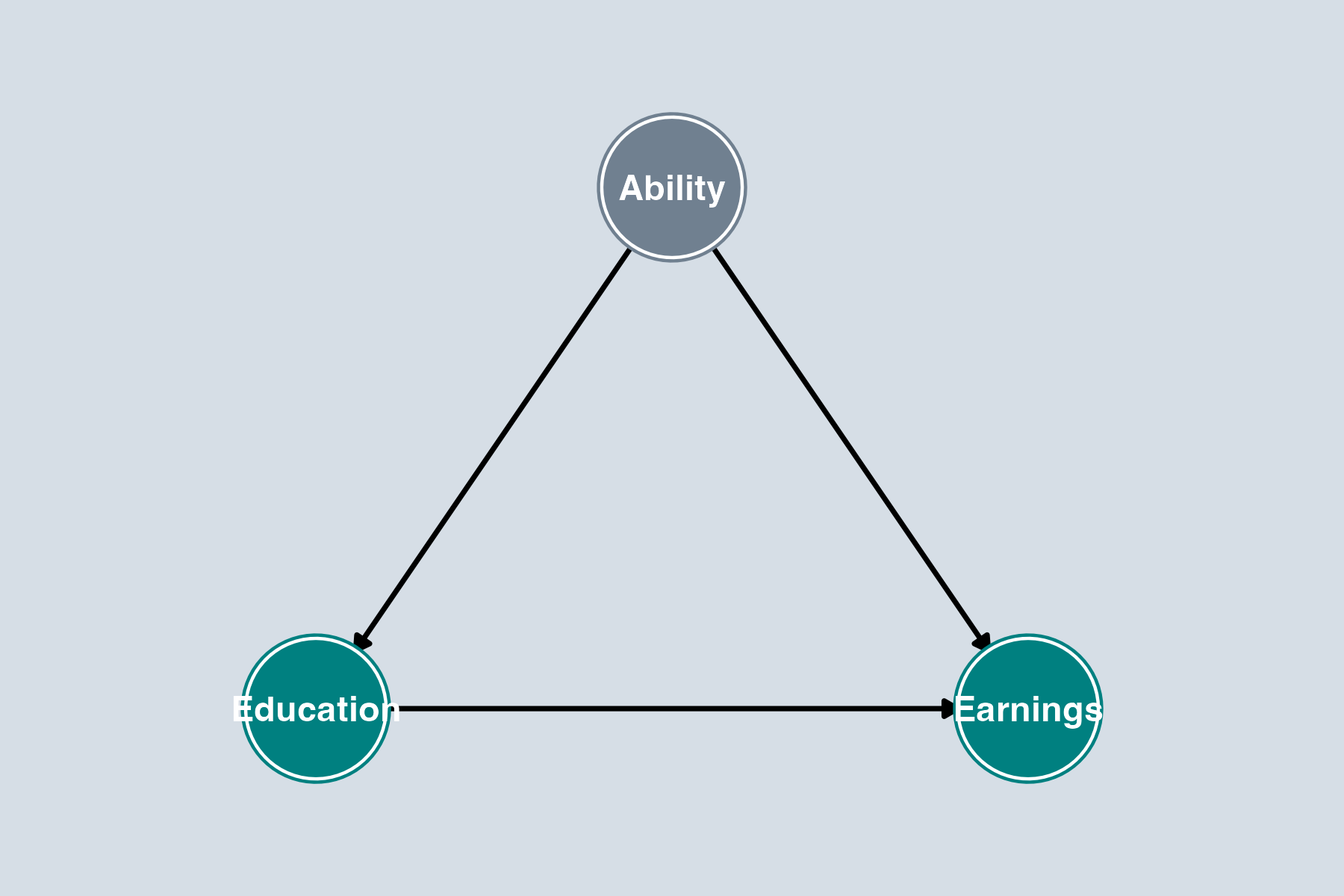
Gray node = unobserved variable
- Causal path? Yes: Education → Earnings
- Backdoor paths? Yes: Education ← Ability → Earnings
- What to control for? Ability
Does Job Training Improve Employment?
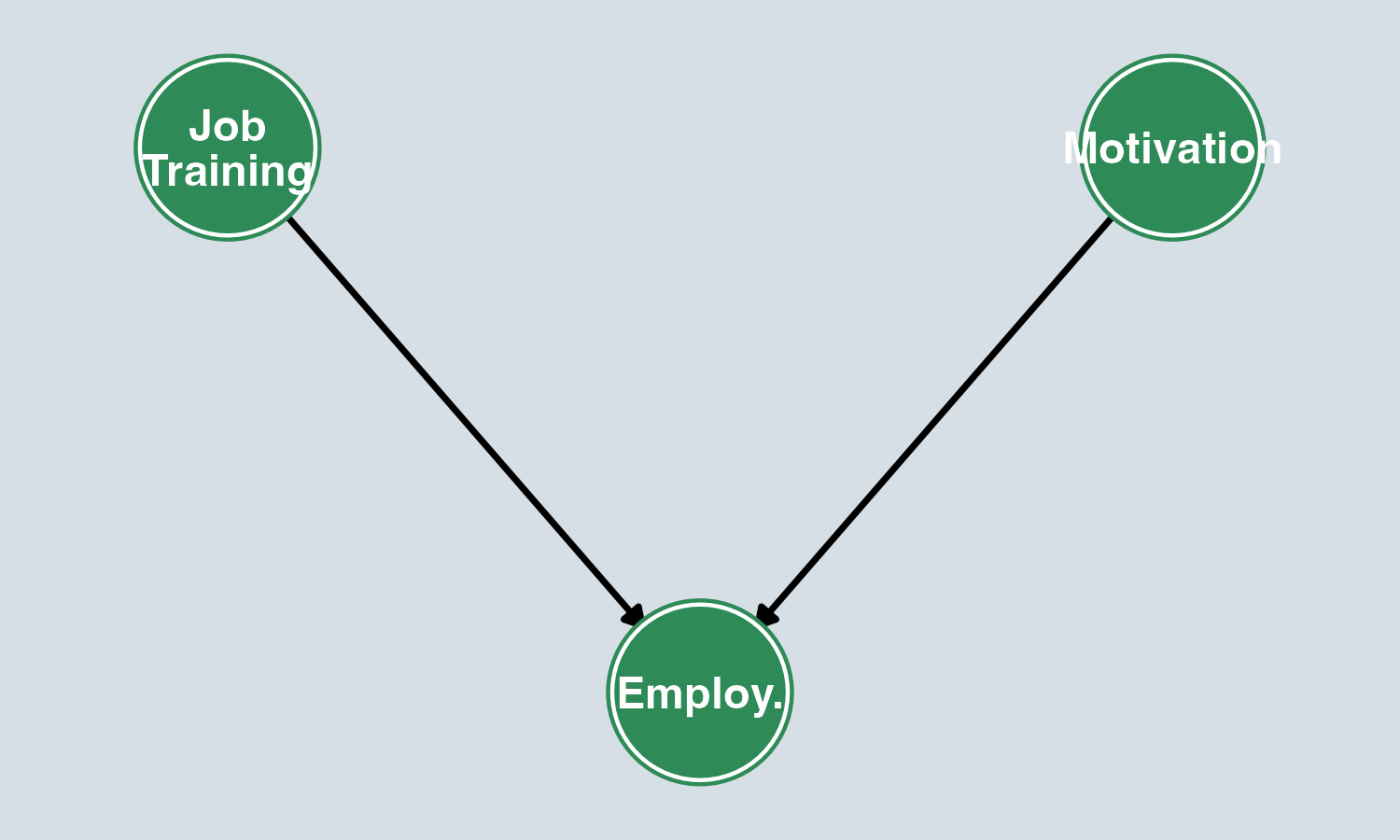
The problem without randomization:
- Motivated workers are more likely to sign up for training
- Motivated workers are also more likely to find jobs
- Backdoor path: Training ← Motivation → Employment
. . .
With an RCT:
- Randomly assign workers to training
- Now Motivation does not cause Training — that arrow is severed
- All backdoor paths are closed by design
Important
This is why randomized controlled trials (RCTs) are the gold standard for causal inference — they eliminate confounding mechanically.
Reverse Causation
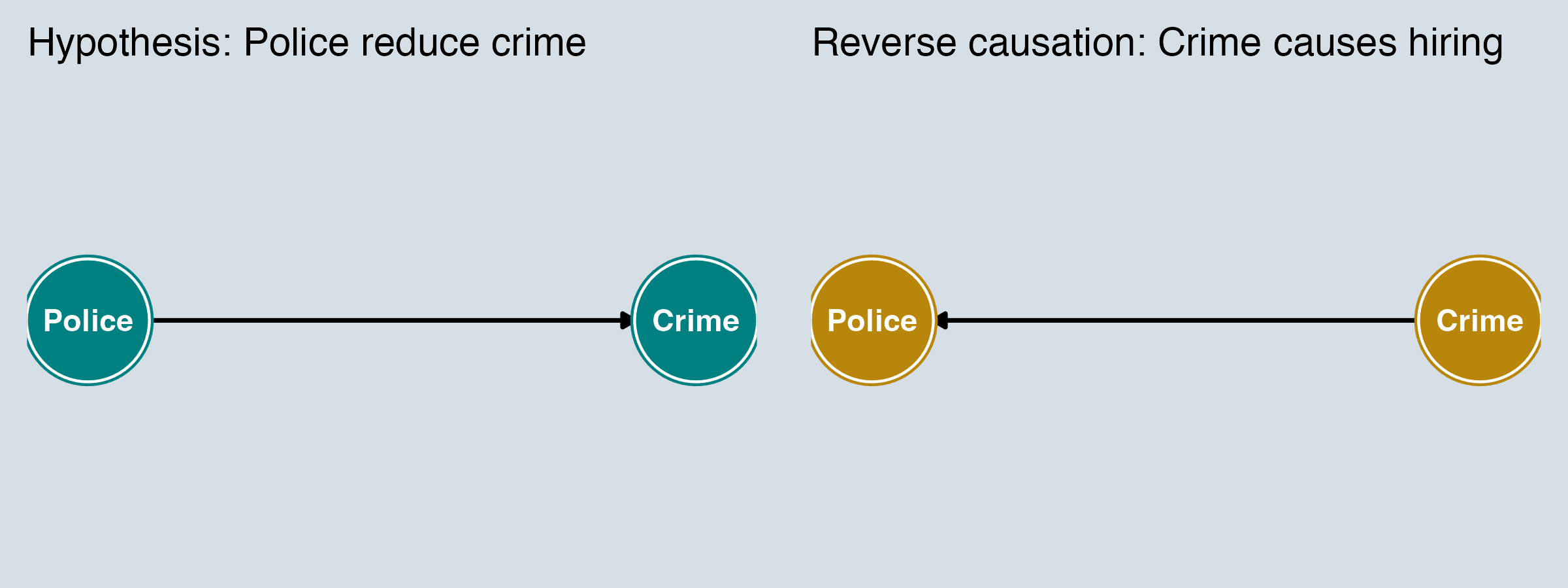
Reverse Causation
Sometimes the arrow between \(X\) and \(Y\) runs in the opposite direction from what we assume.
- We observe a positive correlation between police and crime
- Our hypothesis: More police → less crime
- The problem: Cities with more crime hire more police
In DAG terms: we’ve drawn the wrong DAG. The true DGP has the arrow reversed — or both arrows exist.
Measurement Error
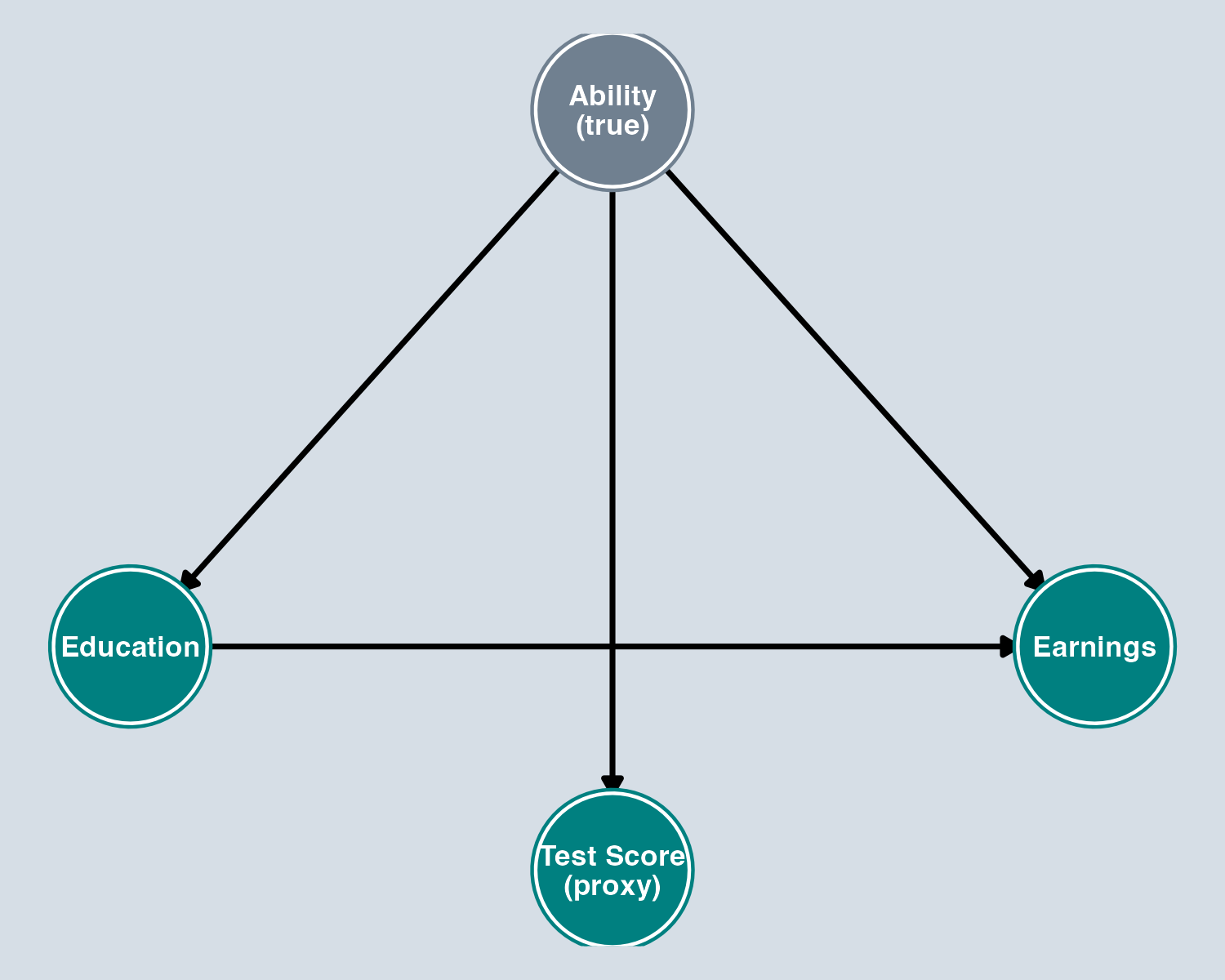
Gray = unobserved
Measurement Error
When we can’t perfectly measure a variable in our DAG, we introduce measurement error.
- We want to control for Ability to close a backdoor path
- We can’t measure Ability directly, so we use a proxy (Test Score)
- But Test Score ≠ Ability (noisy measurement)
- Controlling for the proxy only partially closes the backdoor path
- Result: our estimate is still biased — attenuation bias
Knowledge Check 1: Health Insurance
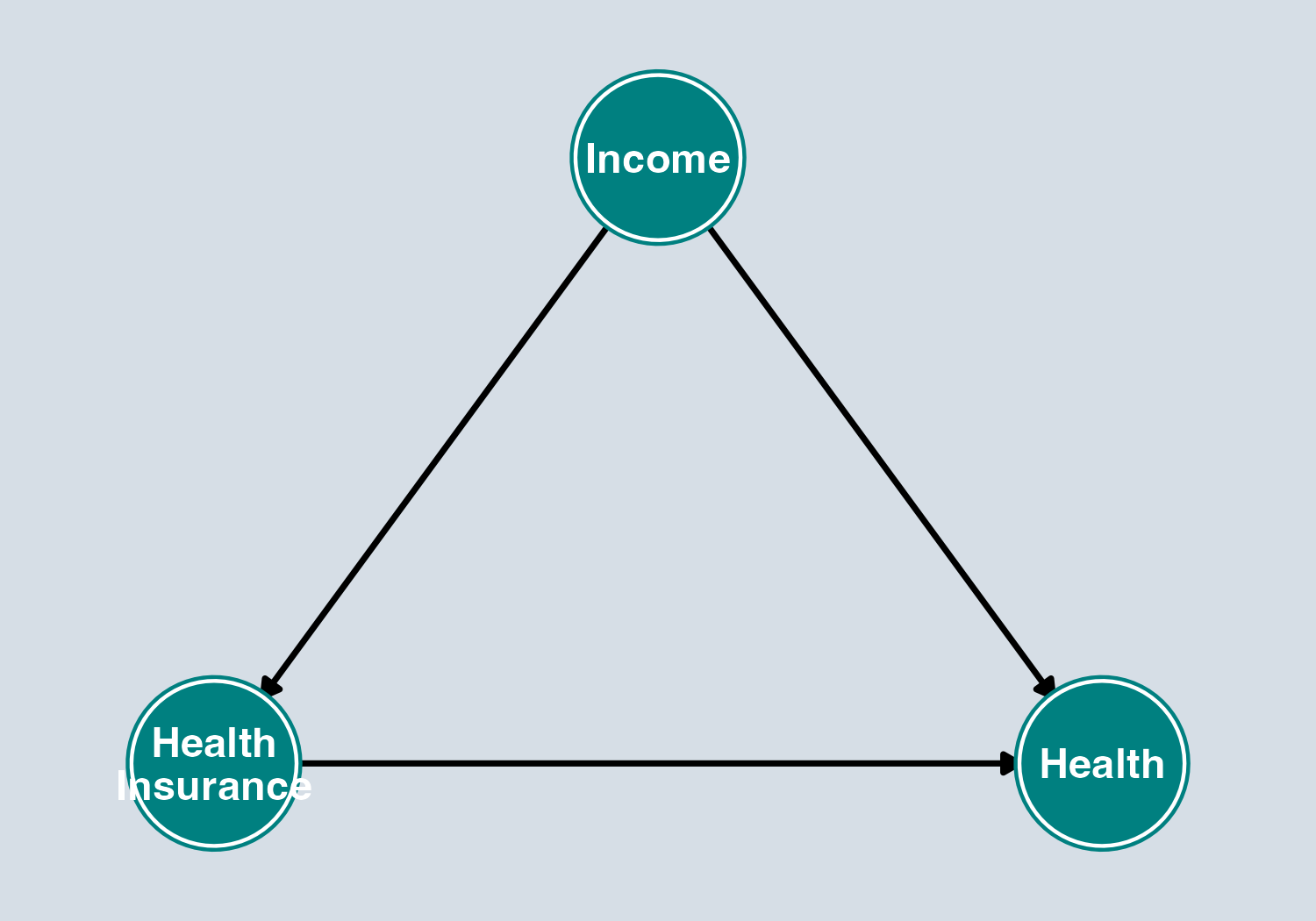
Does Income confound the effect of Health Insurance on Health?
To estimate the effect of Health Insurance on Health, should we control for Income?
Knowledge Check 2: SES and Earnings
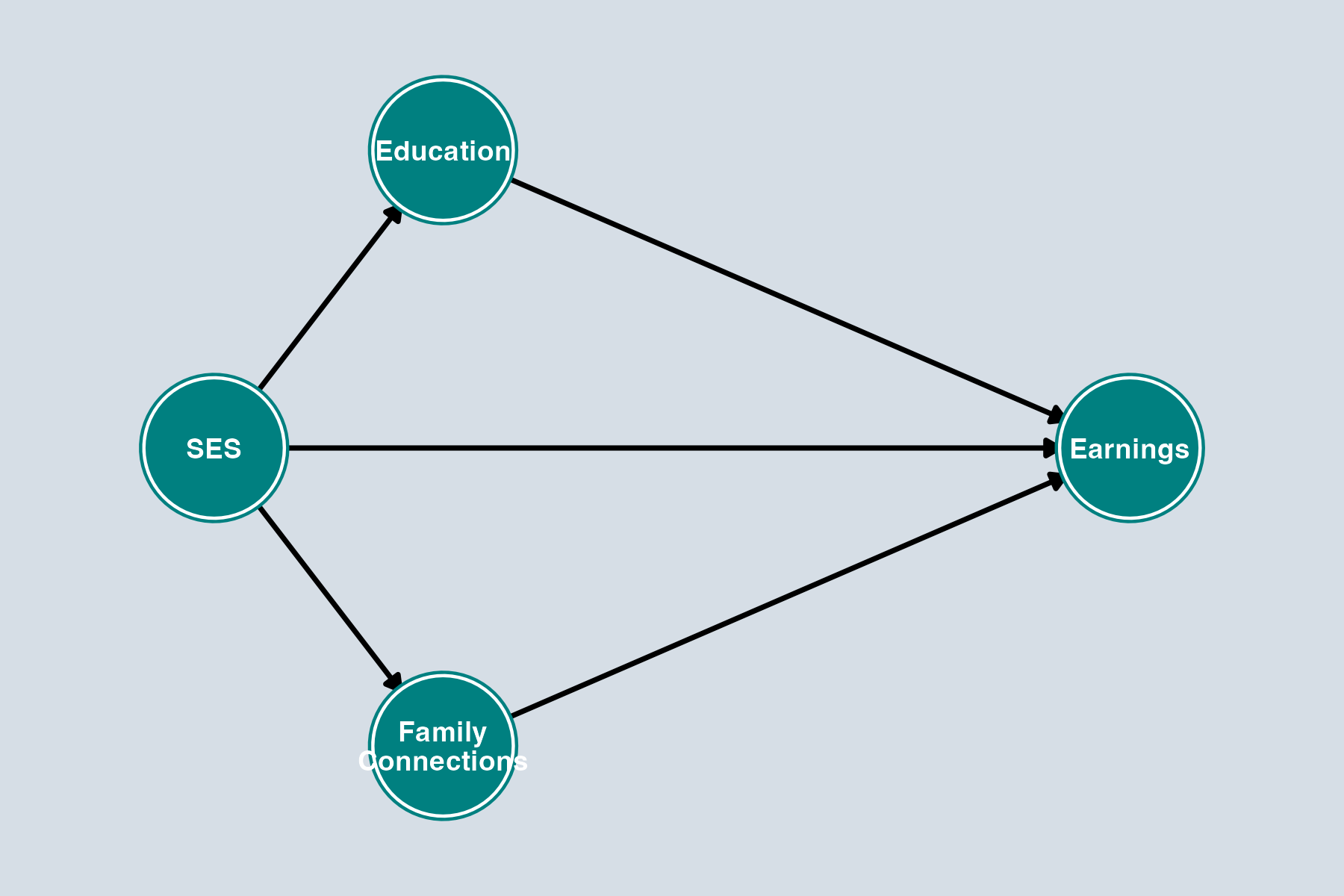
Questions:
- What are the backdoor paths from SES to Earnings?
- What minimal set of variables should we control for?
Case Study: Does Wine Improve Heart Health?

St Leger, Cochrane, & Moore (1979). The Lancet.
In 1979, researchers found a strong negative association between wine consumption and heart disease across 18 developed countries.
The French Paradox Goes Mainstream


Red wine sales in the US jumped nearly 40% in 1992. The idea that wine was good for your heart became conventional wisdom.
But Wait…

Moderate wine drinkers tend to be more educated, wealthier, more physically active, and more likely to have health insurance.
And many “non-drinkers” were actually ex-drinkers who had quit because of health problems.
In DAG terms: What kinds of bias are these?
Better Methods, Different Answers

Using Mendelian randomization — genetic variants as instruments — alcohol at all levels was associated with increased cardiovascular risk.
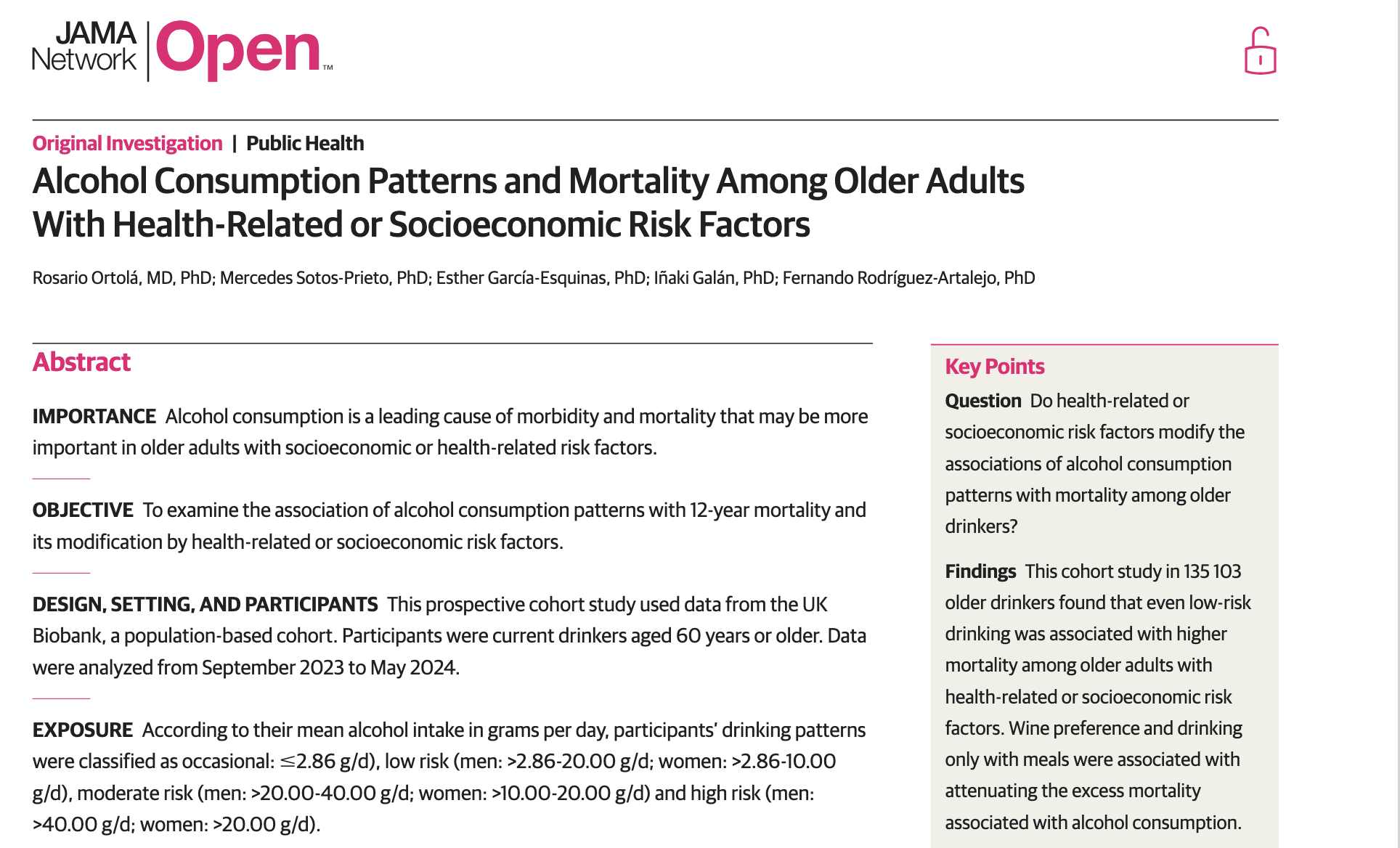
Even among “low-risk” drinkers, alcohol was associated with higher mortality when accounting for health and SES risk factors.