Instrumental Variables
SW Chapter 12
Spring 2026
The Problem in a DAG
To understand how IV solves this, let’s visualize the problem using causal diagrams from Ch 8b.
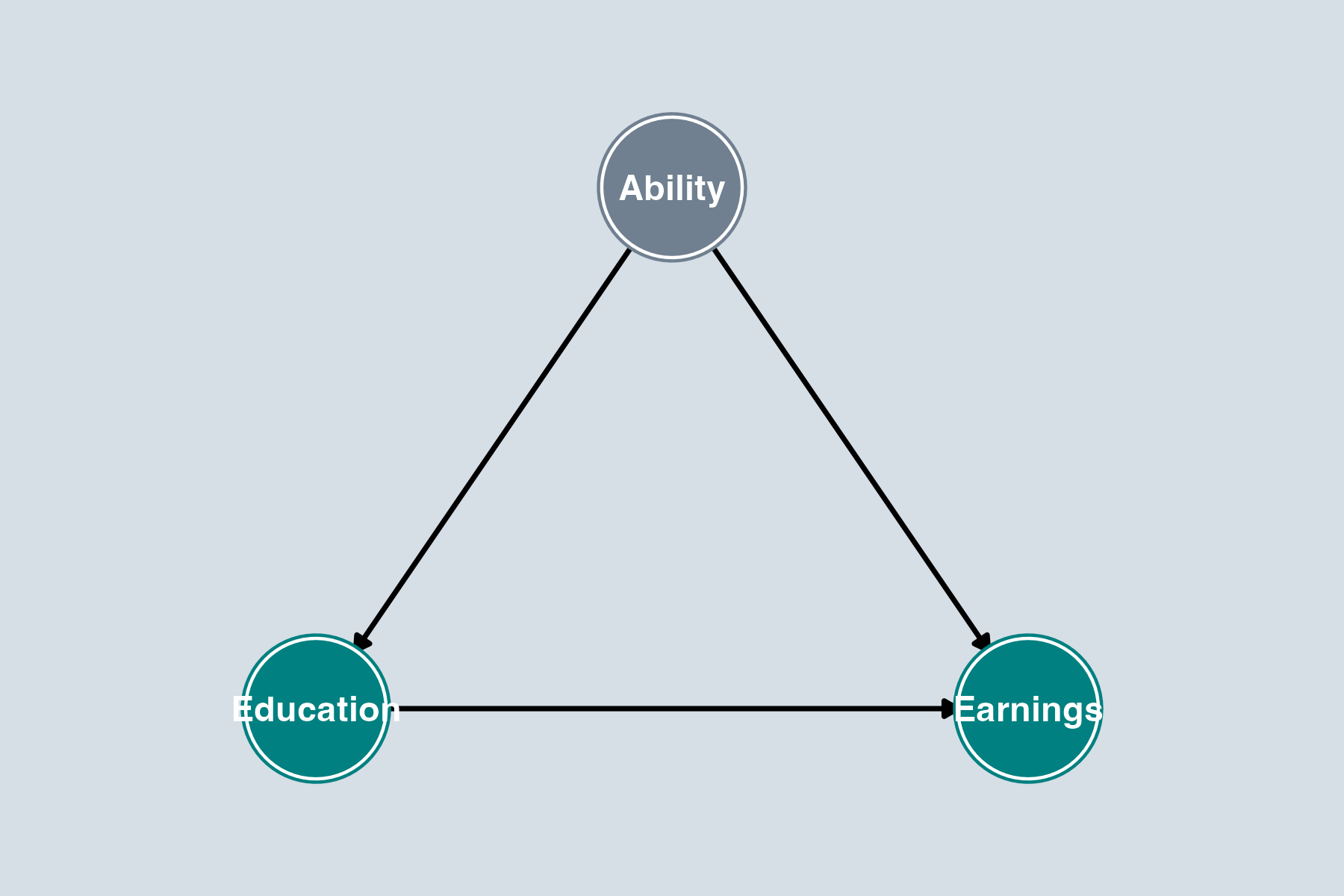
Gray = unobserved
From Ch 8b, we know this DAG:
- Causal path: Education → Earnings ✓
- Backdoor path: Education ← Ability → Earnings ✗
The backdoor path is open and Ability is unobserved.
- Can’t control for it (Ch 6/7)
- Can’t difference it out (Ch 10)
- We need a new tool to close this path.
The IV Solution in a DAG
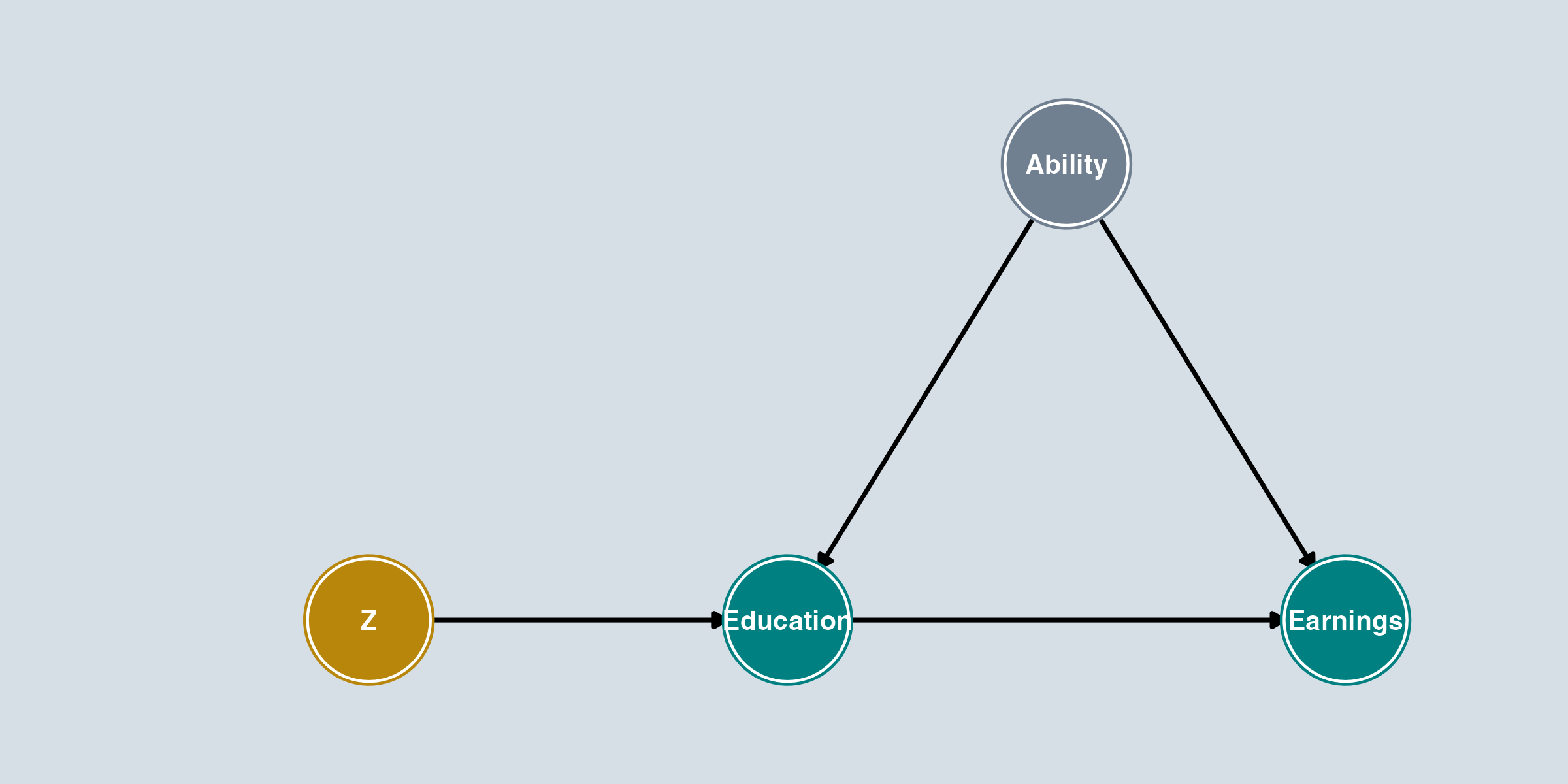
Gold = instrument, Gray = unobserved
Add an instrument \(Z\) to the DAG. A valid instrument must satisfy:
- Z → Education: \(Z\) affects \(X\) (relevance)
- No Z ← Ability: \(Z\) is not connected to unobserved confounders (exogeneity)
- No Z → Earnings: \(Z\) does not directly affect \(Y\) (exclusion)
Key Insight
IV works by isolating the variation in Education that comes only from \(Z\). Since \(Z\) has no connection to Ability and no direct effect on Earnings, this variation is “clean” — free of confounding.
Demand for Cigarettes
Broad public policy interest in reducing cigarette consumption.
\[sales_i = \beta_0 + \beta_1 price_i + u_i\]
- Price may be correlated with omitted variables in \(u\): firms set prices based on demand conditions
- When state \(i\) has unusually high demand (\(u_i\) high), prices are higher too
- This is simultaneous causality: sales depend on prices, but prices also depend on sales
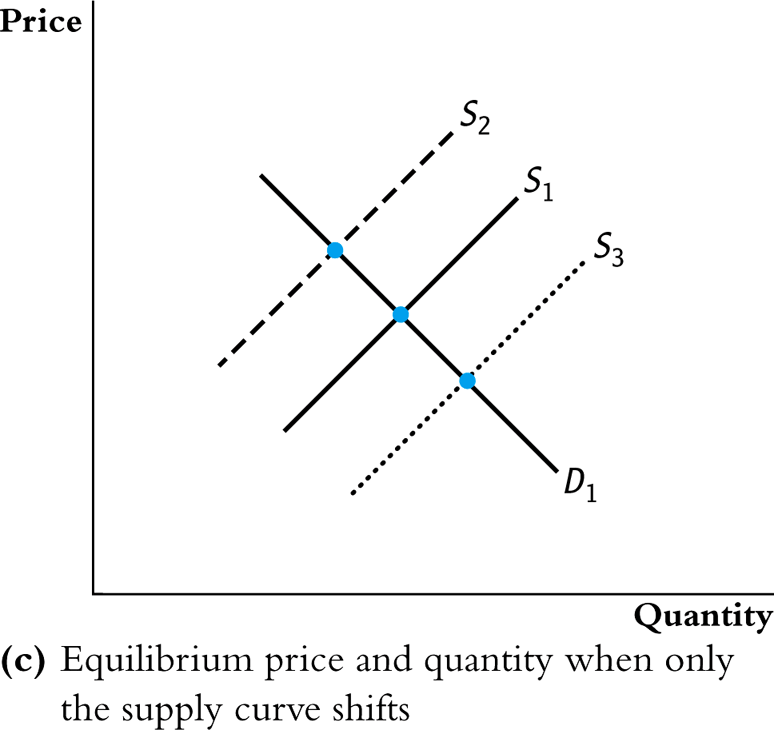
The identification problem: When both supply and demand shift, equilibrium data trace out neither curve — just a scatter of equilibrium points.
We need something that shifts supply without shifting demand.
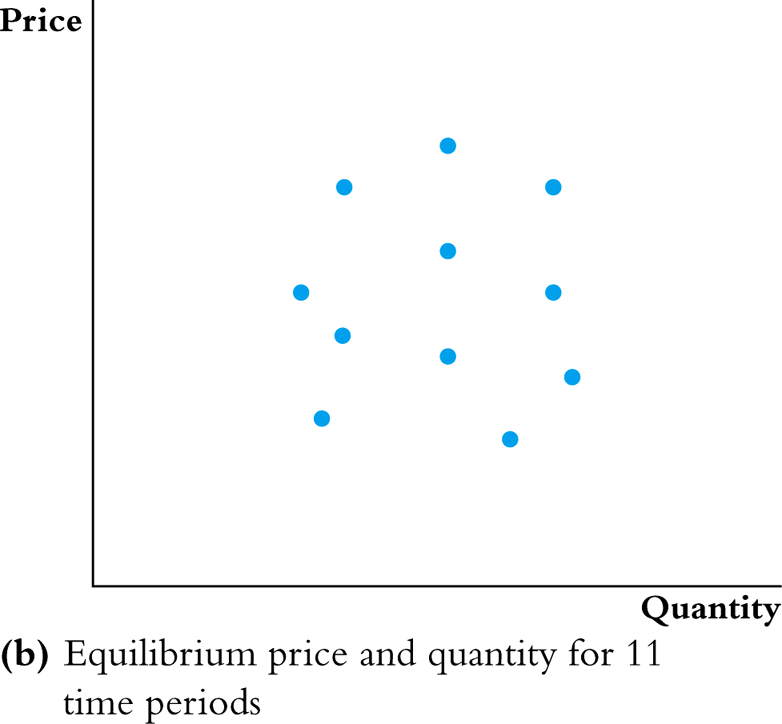
The IV Intuition
If we can hold demand fixed and only observe supply shifting:
- The equilibrium points trace out the demand curve
- The instrument shifts supply without directly affecting demand — it moves \(X\) without directly affecting \(Y\)
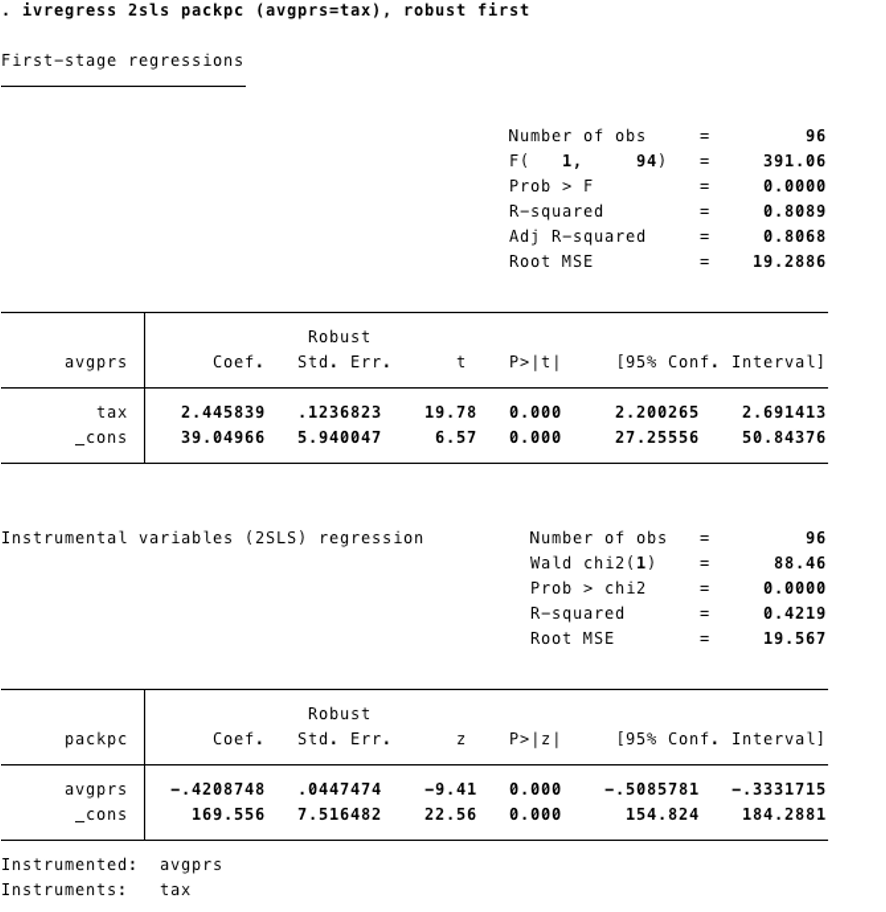
Viewing Both Stages with first
ivregress 2sls packpc (avgprs=tax), robust first
The first option displays the first-stage regression alongside the second stage.
Adding Exogenous Controls
\[sales_i = \beta_0 + \beta_1 price_i + \beta_2 income_i + u_i\]
- Income per person at the state level may affect cigarette sales
- Income is not determined simultaneously with cigarette demand
- We assume income is uncorrelated with the composite error \(u\)
- 2SLS can handle variables not treated as endogenous
- Income enters both stages:
- First stage: helps predict price
- Second stage: controls for income’s direct effect on sales
ivregress 2sls packpc (avgprs=tax) incomepop, robust first

Comparing All Specifications
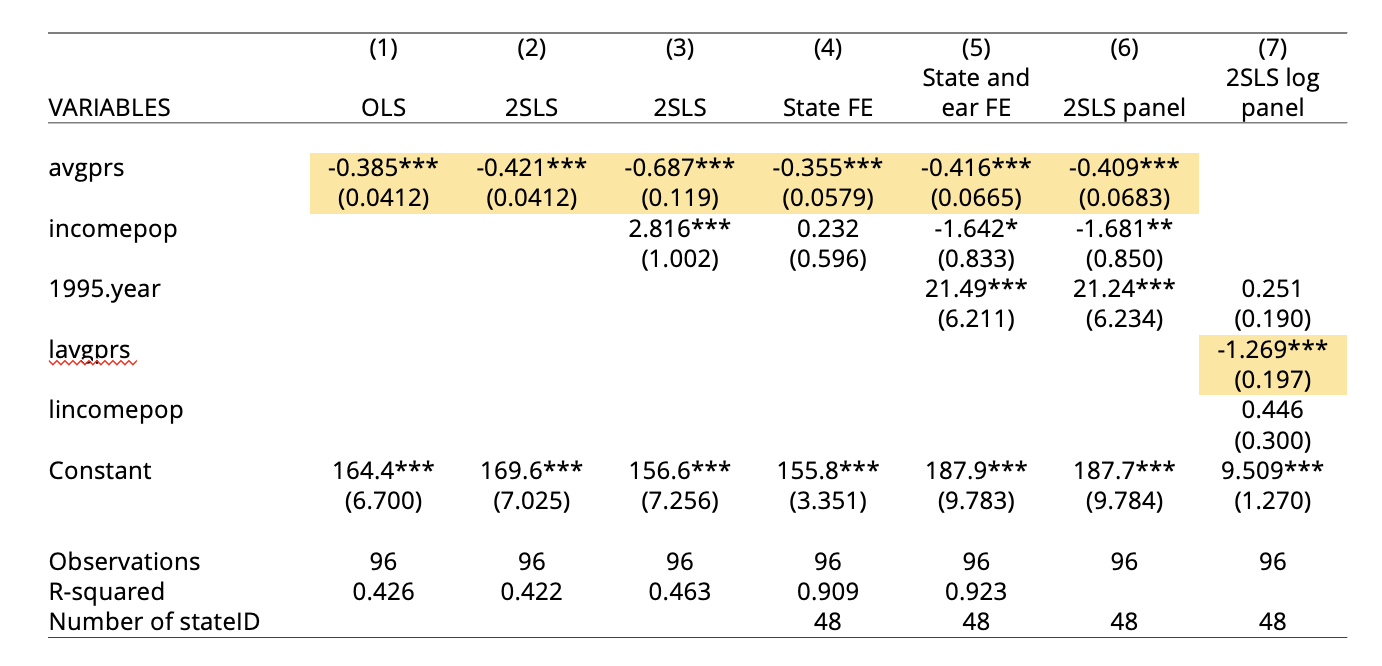
Best Elasticity Estimate
Column 7 adds logs so \(\beta_1\) is an elasticity: when price rises 1%, sales fall 1.3%. The CI of \((-1.53, -1.00)\) lies entirely below \(-1\), so we can reject that demand is inelastic.
What Changes Across Specifications?
Adding state + year FEs and an IV for price (sales tax) moves the coefficient from OLS’s biased estimate toward a credible causal effect.
AK (1991): First Stage
Does quarter of birth actually predict education?
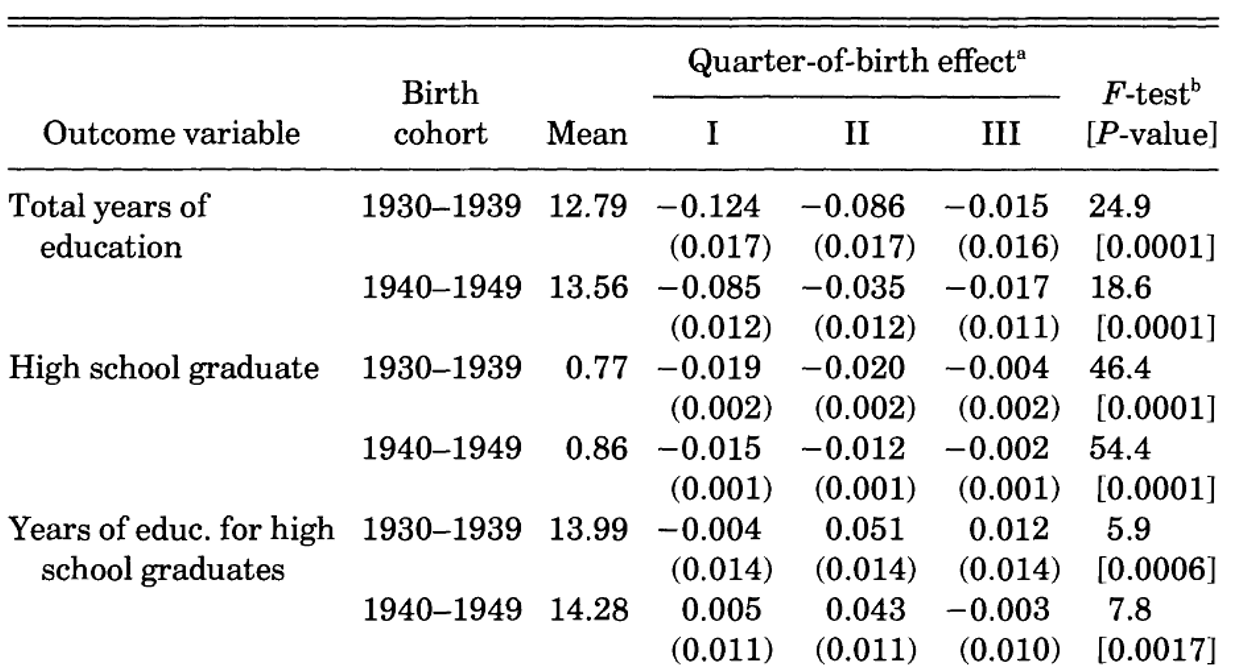
Born in Q1 → significantly less education. F-tests are strong for total years.
AK (1991): The Earnings Pattern
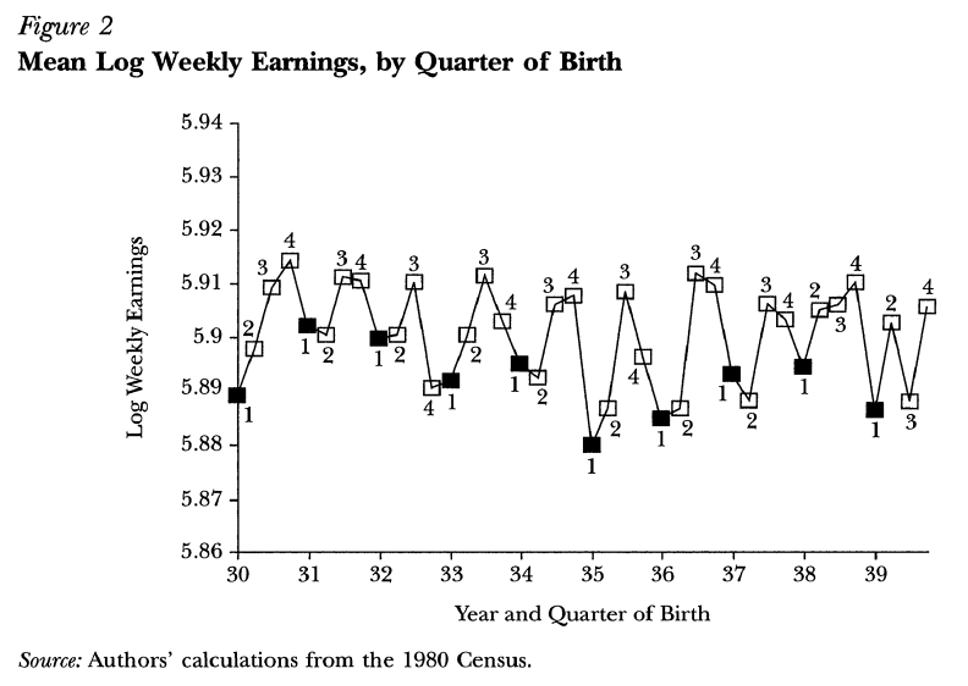
Mean log weekly earnings by quarter of birth (1980 Census). The sawtooth pattern mirrors the education pattern — Q1 births earn less.
AK (1991): OLS vs. TSLS Estimates
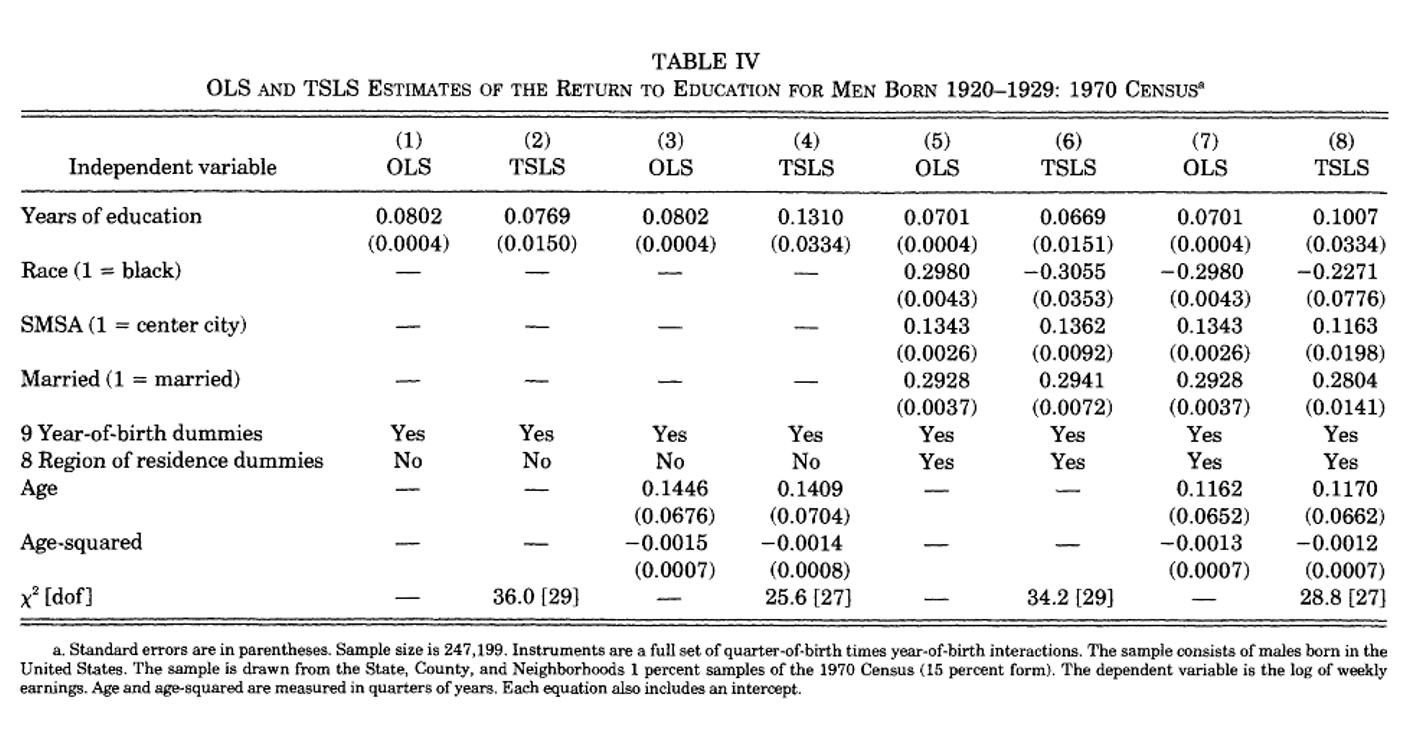
OLS and TSLS estimates of returns to education, men born 1920–1929 (1970 Census, \(n = 247{,}199\)). Instruments: quarter-of-birth × year-of-birth interactions.
Puzzle: IV > OLS?
If ability bias is the main problem, we’d expect OLS to overestimate the return to schooling — so IV should be smaller than OLS. But here IV is larger. Two possible reasons:
- Measurement error in self-reported years of education attenuates OLS toward zero; IV corrects it
- LATE \(\neq\) ATE: compliers here are marginal dropouts, who may have higher returns to each extra year than the average student
Also note: IV standard errors are much larger than OLS — we’re using less variation, so estimates are noisier.
Stinebrickner and Stinebrickner (2008): Results
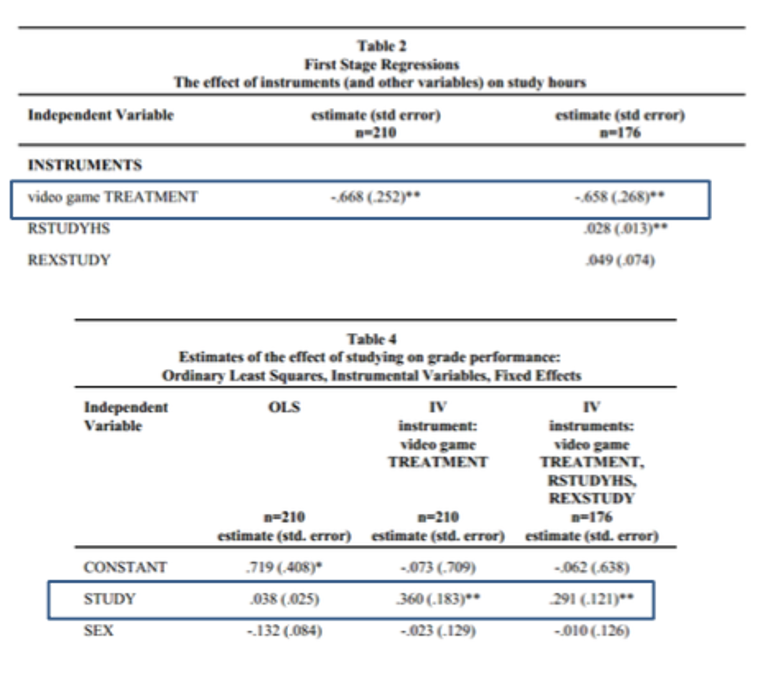
OLS coefficient on study = 0.038; IV coefficient = 0.36 (much larger). Why? Selection bias — students who study more tend to be weaker students compensating with extra effort (negative selection). IV corrects this by using only the variation in study time driven by the random video-game assignment.