Difference-in-Differences
SW Chapter 10 (Part 2)
Spring 2026
Motivating Example: Garbage Incinerator
Question: What is the effect of a garbage incinerator on nearby housing prices?
After the incinerator was built:
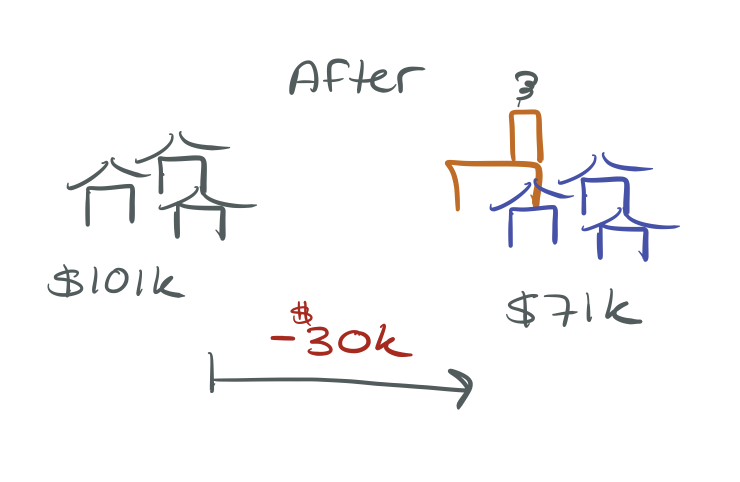
\[\widehat{rprice} = 101{,}308 - 30{,}688 \cdot nearinc\]
Houses near the incinerator sell for ~$30k less. Did the incinerator cause this?
Not So Fast…
Look at the relationship before the incinerator was built:
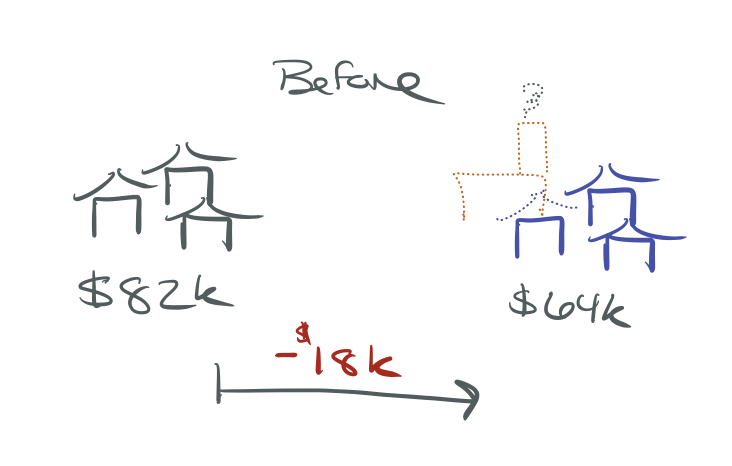
\[\widehat{rprice} = 82{,}517 - 18{,}824 \cdot nearinc\]
The incinerator was built in a place where housing prices were already depressed!
The $30k gap reflects both the incinerator effect and pre-existing differences.
The Core Logic
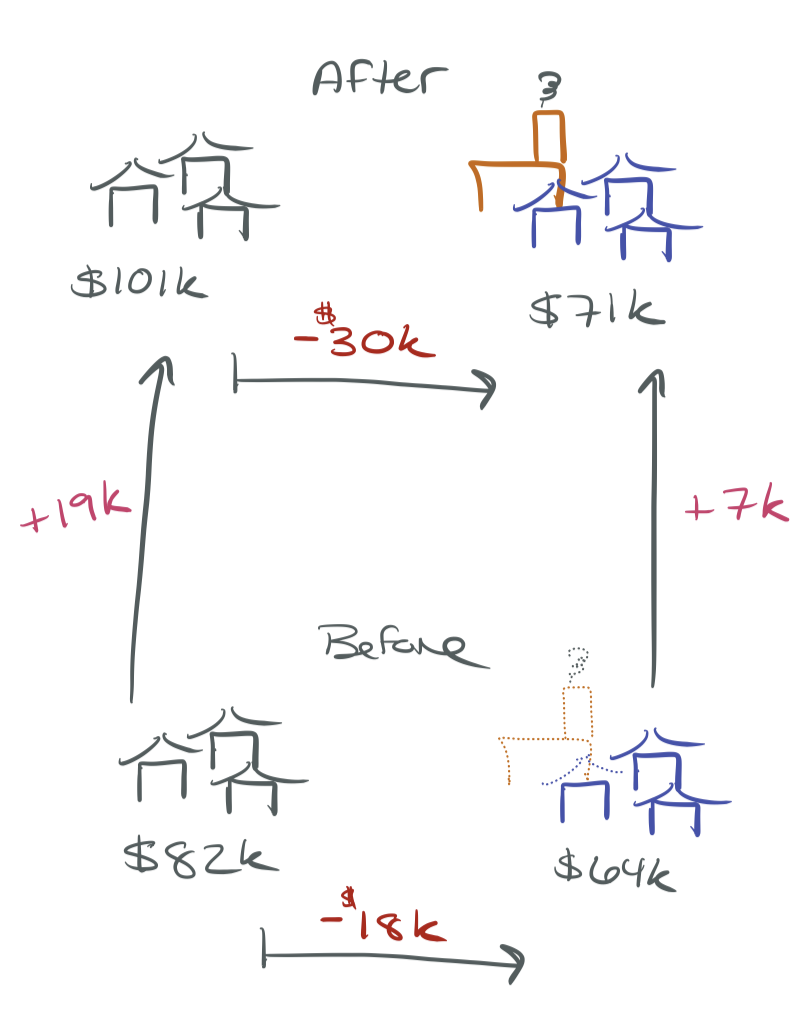
Subtract out the pre-existing difference:
\[\begin{aligned} \hat{\delta}_1 &= \underbrace{(-30{,}688)}_{\text{after gap}} - \underbrace{(-18{,}824)}_{\text{before gap}} \\ &= -11{,}864 \end{aligned}\]
The incinerator reduced nearby prices by ~$12k — not $30k.
The 2×2 Table
The difference of differences:
| Before | After | \(\Delta\) | |
|---|---|---|---|
| Control (far) | $82,517 | $101,308 | +$18,790 |
| Treatment (near) | $63,693 | $70,619 | +$6,927 |
| Treat \(-\) Control | −$18,824 | −$30,688 | −$11,864 |
\[\begin{aligned} &\underbrace{(70{,}619 - 63{,}693)}_{\Delta \text{ treat}} - \underbrace{(101{,}308 - 82{,}517)}_{\Delta \text{ control}} \\ &\quad = {\color{red}-11{,}864} \end{aligned}\]
DiD Graphically
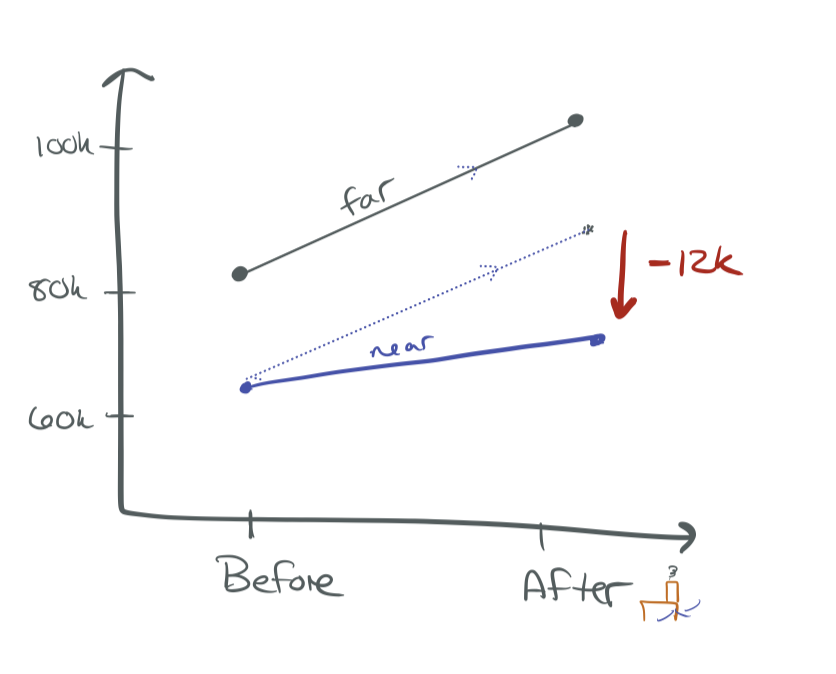
The dashed line shows where near-incinerator prices would have been if they followed the same trend as far-away prices.
The DiD estimate is the vertical gap between:
- What actually happened to the treatment group
- The counterfactual: what would have happened without treatment
DiD Animated
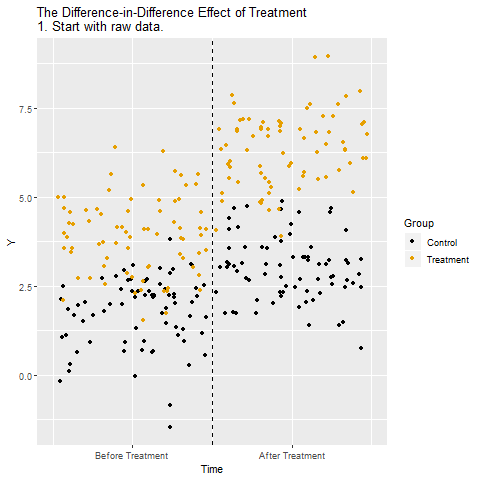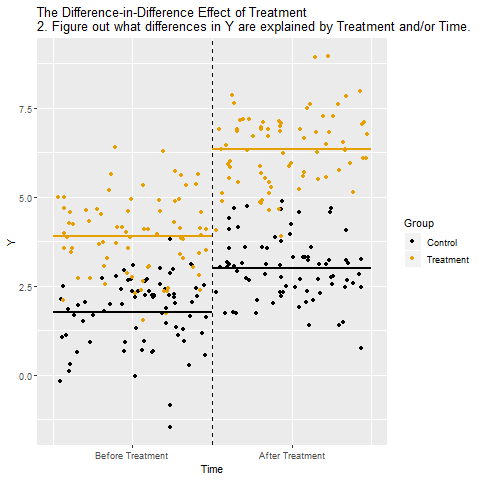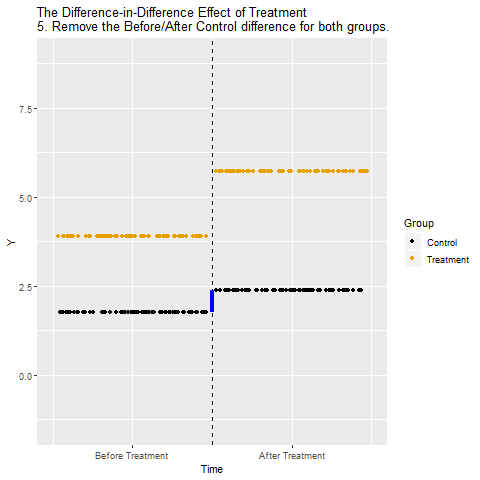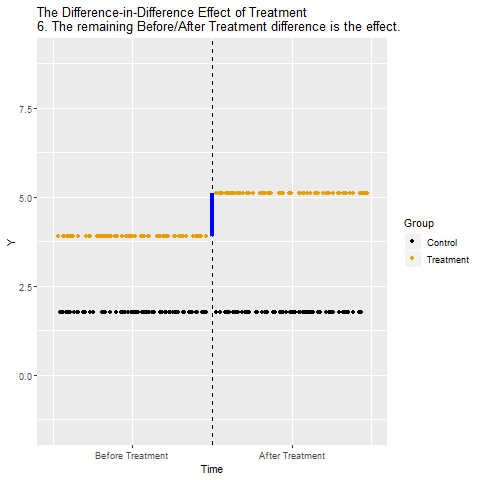
Watch the steps:
- Raw data: two groups over time
- Collapse to group means
- Measure the control group’s time trend
- Subtract that trend from the treatment group
- What remains = the DiD estimate
The key: use the control group’s trajectory to build the counterfactual for the treatment group.
Parallel Trends Holds
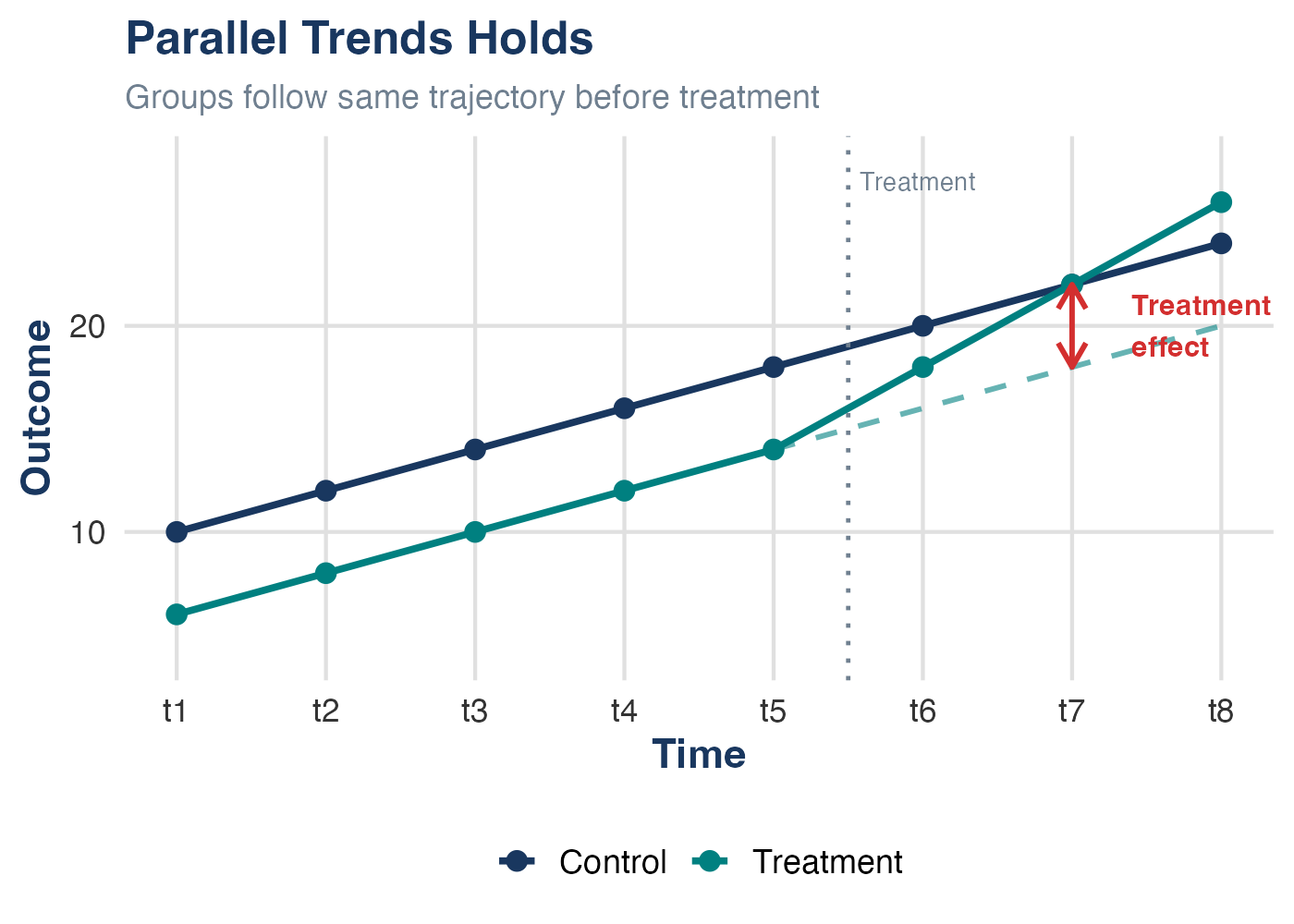
Groups follow the same trajectory before treatment. The treatment effect is the gap between the actual outcome and the counterfactual (dashed line).
The dashed line = the counterfactual: where the treatment group would have been if it followed the control group’s trend.
Parallel Trends Violated
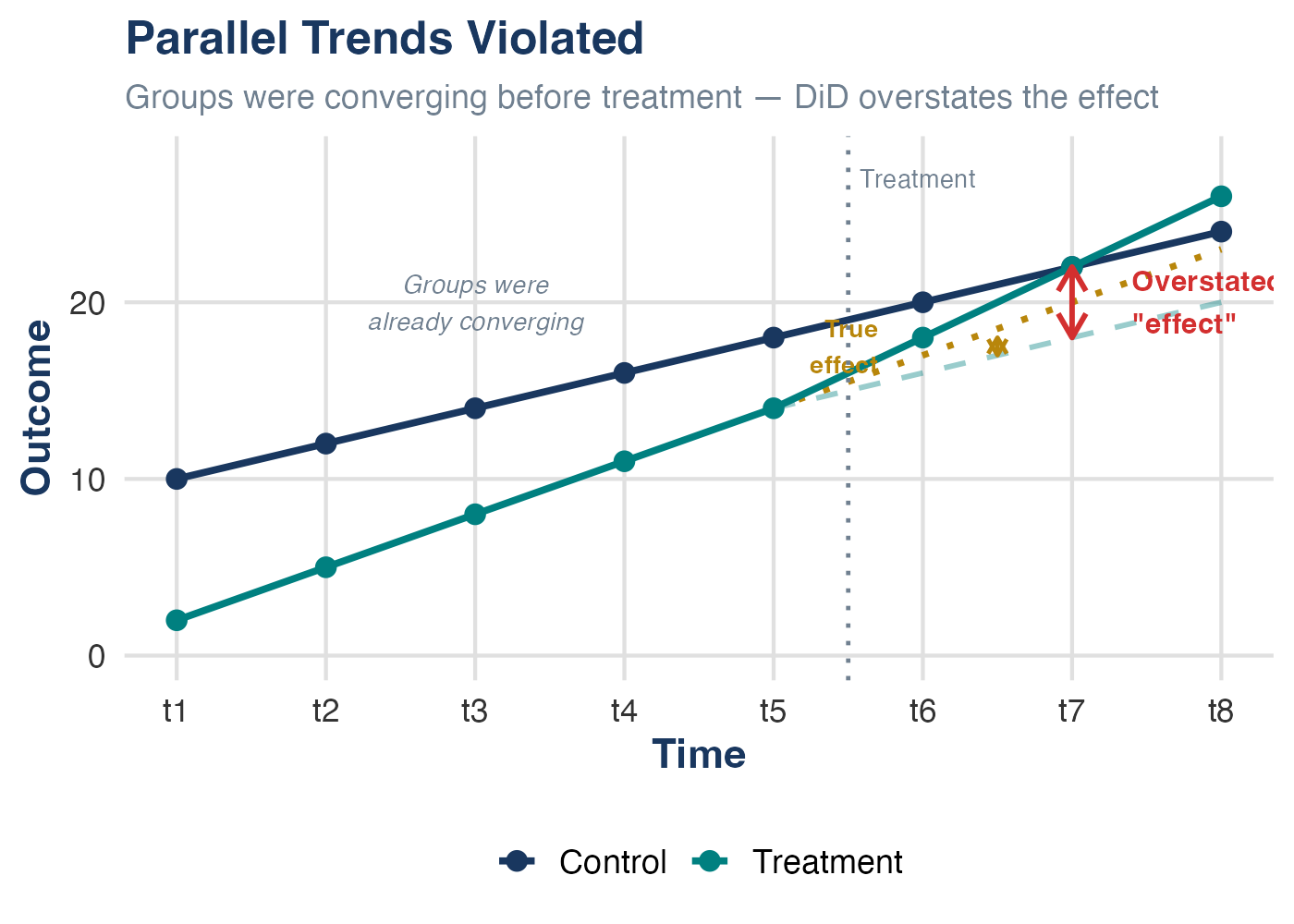
Groups were converging before treatment. DiD attributes the continued convergence to the treatment — overstating the true effect.
The gold dotted line = the true counterfactual (continuing convergence). The dashed line = what DiD incorrectly assumes. The difference between the two is the bias.