Problem set 3
Welcome
Note that this is your last problem set before the next exam!
See the exercises below, or you can download them as a pdf. You can download the data file you need for question 6 here, along with information on the variable definitions here
What do I submit?
- Your written answers to exercise questions. If you work on a piece of paper, please scan using some sort of phone software (like Microsoft Lens or Adobe Scan) rather than just taking a picture.
- A do-file that runs your Stata analysis (for questions 6 and 7).
- A log file that includes the output from running your do-file (for question 6 and 7).
Exercises
-
Suppose that we want to estimate the effects of alcohol consumption ($alcohol$) on college grade point average ($colGPA$). In addition to collecting information on alcohol consumption and grade point averages, we also obtain attendance information (say, percentage of lectures attended, $attend$). A standardized test score (say, $SAT$) and high school GPA ($hsGPA$) are also available.
a. Should we include $attend$ along with alcohol as explanatory variables in a multiple regression model? What would be the interpretation of $\beta_{alcohol}$ if we did?
b. Should $SAT$ and $hsGPA$ be included as explanatory variables? Explain.
-
A researcher plans to study the causal effect of police on crime, using data from a random sample of U.S. counties. She plans to regress the county’s crime rate on the (per capita) size of the county’s police force.
a. Explain why this regression is likely to suffer from omitted variable bias. Which variables would you add to the regression to control for important omitted variables?
b. Use your answer to (a) and the expression for omitted variable bias (from the slides or textbook) to determine whether the regression will likely over- or underestimate the effect of police on the crime rate. (That is, is $\hat{\beta_1}>\beta_1$, or that $\hat{\beta_1} < \beta_1$?)
-
Critique each of the following proposed research plans. Your critique should explain any problems with the proposed research and describe how the research plan might be improved. Include discussion of any additional data that needs to be collected, and the appropriate statistical techniques for analyzing those data.
a. A researcher is interested in determining whether a large aerospace firm is guilty of gender bias in setting wages. To determine potential bias, the researcher collects salary and gender information for all of the firm’s engineers. The researcher then plans to conduct a “difference in means” test to determine whether the average salary for women is significantly less than the average salary for men.
b. A researcher is interested in determining whether time in prison has a permanent effect on a person’s wage rate. He collects data on a random sample of people who have been out of prison for at least 15 years. He collects similar data on a random sample of people who have never served time in prison. The data set includes information on each person’s current wage, education, age, ethnicity, gender, tenure (time in current job), occupation, and union status, as well as whether the person has ever been incarcerated. The researcher plans to estimate the effect of incarceration on wages by regressing wages on an indicator variable for incarceration, including in the regression the other potential determinants of wages such as education, tenure, union status, and so on.
-
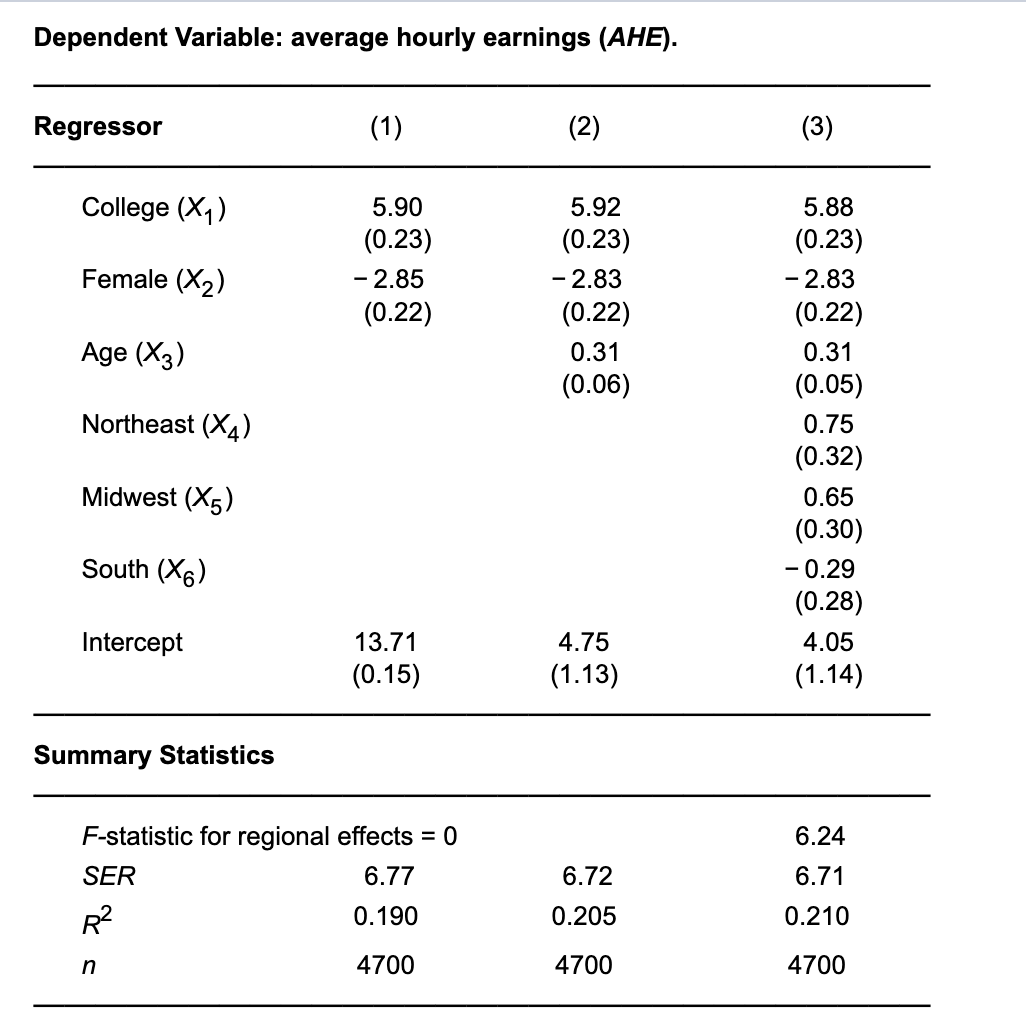
Consider a dataset that contains information on 4700 full-time full-year workers. The highest educational achievement for each worker was either a high school diploma or a bachelor’s degree. The worker’s ages ranged from 25 to 45 years. The data set also contains information on the region of the country where the person lived, marital status, and number of children. See below for variable definitions.
a. Is the college-high school earnings difference estimated from this regression statistically significant at the 5% level? Construct a 95% confidence interval of the difference.
b. Do there appear to be important regional differences in hourly earnings? Use an appropriate hypothesis test to explain your answer.
| Variable | Definition |
|---|---|
| AHE | average hourly earnings (in 2005 dollars) |
| College | 1 if college, 0 if high school |
| Female | 1 if female, 0 if male |
| Age | age (in years) |
| Ntheast | 1 if Region = Northeast, 0 otherwise |
| Midwest | 1 if Region = Midwest, 0 otherwise |
| South | 1 if Region = South, 0 otherwise |
| West | 1 if Region = West, 0 otherwise |
-
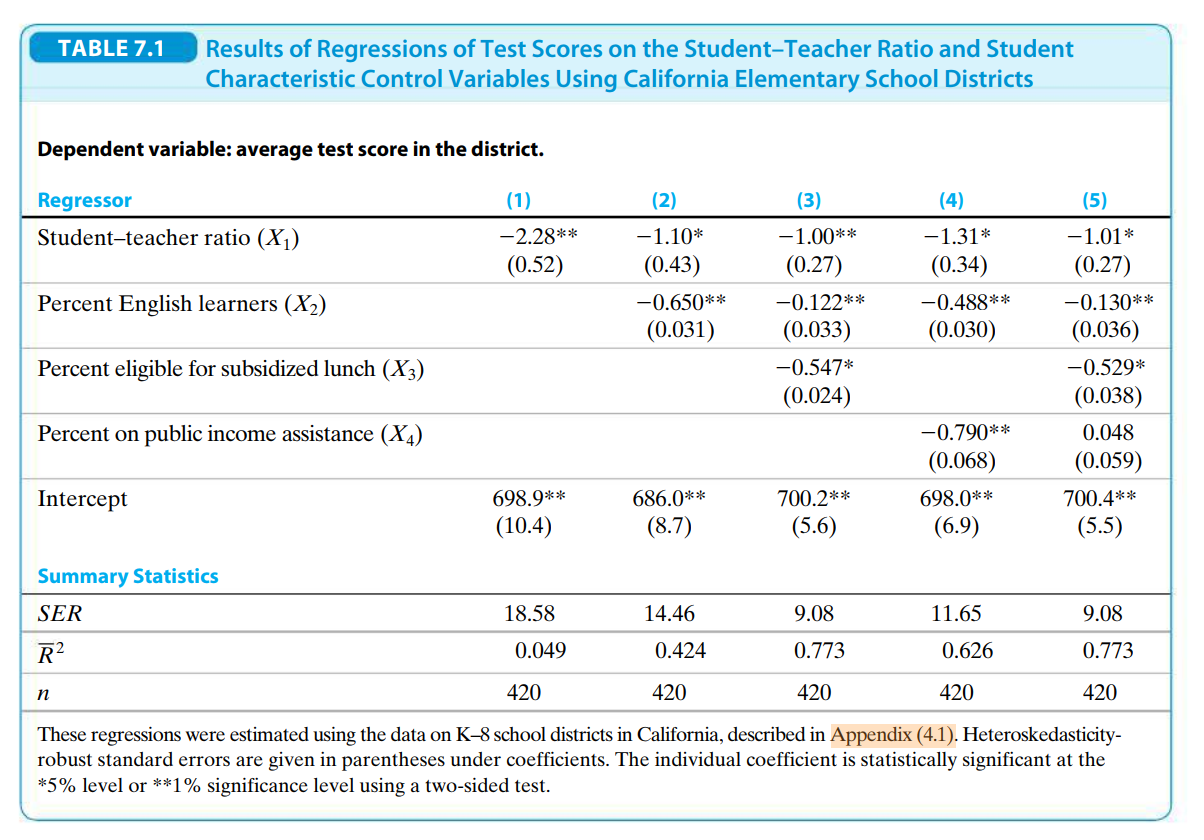
Consider the regression results below and do the following:
a. Construct the $R^2$ for each of the regressions
b. Construct the homoskedasticity-only $F$-statistic for testing $\beta_3 = \beta_4 = 0$ shown in column (5). Is the statistic significant at the 5% level?
c. Construct a 99% confidence interval for $\beta_1$ for the regression in column (5)
-
Download the dataset growth.dta, which contains data on average growth rates from 1960 through 1995 for 65 countries, along with variables that are potentially related to growth. You can download a detailed description of all variable names is available here. For all questions, exclude Malta, which has an extremely high trade share.
a. Write the population model for a regression of
growthontradeshare,yearsschool,rev_coups,assassinations, andrgdp60. Then estimate it using OLS with heteroskedasticity-robust standard errors.b. What is the value of the coefficient on
rev_coups? Interpret the value of this coefficient. Is it large or small in a real-world sense?c. Use the regression to predict the average annual growth rate for a country that has average values for all regressors.
d. Test whether the political variables
rev_coupsandassassinations, taken as a group, can be omitted from the regression. What is the p-value of the F-statistic?e. After running your regression, pick one country in your sample. Report its actual value of
growth, its fitted (predicted) value, and its residual. In one sentence, what does that residual mean?f. Under what assumptions is the OLS estimator BLUE? For this regression, which of those assumptions are likely to hold, which are likely violated, and for which would you need more information? (One short sentence per assumption is enough.)
-
Consider the regression in Question 6:
growthontradeshare,yearsschool,rev_coups,assassinations, andrgdp60.a. Give an example of a variable that is likely to be in the error term and would not violate the zero conditional mean assumption. Explain in one sentence.
b. Give an example of a variable that is likely to be in the error term and would violate the zero conditional mean assumption. Explain in one sentence.